

撒花
这个Blog终于开通啦
时间:2017/9/24
博主:蠢纯
注意事项
如果有问题请与我私聊,联系方式:QQ499154897
请勿随意转载内容
如果有侵权的地方定当删除
1. 拖延了6天才算基本写完后台,拖延症越来越严重了
2. 后台采用的php,做了一定的防护()
3. 现在就来梳理下搭建后台遇到的一些小问题吧
webstorm批量查找,批量替换快捷键
a. Ctrl + Shift + F : 批量查找
b. Ctrl + Shift + R : 批量替换
c. Ctrl + Alt + I : 整理缩进
准备环境:
1、ubuntu系统,(我在ubuntu的12.04,14。04以及16.04测试通过。其他版本请自行测试,可参考官方文档!)
2、保持网络
3、发现配置代码被当成标签用了,以后凡是代码用图片
1、如果你安装 Ubuntu 的时候不是用的 “hadoop” 用户,那么需要增加一个名为 hadoop 的用户。
首先按 ctrl+alt+t 打开终端窗口,输入如下命令创建新用户
sudo useradd -m hadoop -s /bin/bash
2、接着使用如下命令设置密码,可简单设置为 hadoop,按提示输入两次密码:(输入密码时,密码不可见)
sudo passwd hadoop
可为 hadoop 用户增加管理员权限,方便部署,避免一些对新手来说比较棘手的权限问题:
sudo adduser hadoop sudo
3、最后注销当前用户(点击屏幕右上角的齿轮,选择注销),在登陆界面
使用刚创建的 hadoop 用户进行登陆。
4、用 hadoop 用户登录后,我们先更新一下 apt,后续我们使用 apt 安装软件,如果没更新可能有一些软件安装不了。按 ctrl+alt+t 打开终端窗口,执行如下命令:
sudo apt-get update
5、后续需要更改一些配置文件,我比较喜欢用的是 vim(vi增强版,基本用法相同),建议安装一下(如果你实在还不会用 vi/vim 的,请将后面用到 vim 的地方改为 gedit,这样可以使用文本编辑器进行修改,并且每次文件更改完成后请关闭整个 gedit 程序,否则会占用终端)
sudo apt-get install vim
安装软件时若需要确认,在提示处输入 y 即可。

6、集群、单节点模式都需要用到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上面运行命令),Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server:
sudo apt-get install openssh-server
安装后,可以使用如下命令登陆本机:
ssh localhost
此时会有如下提示(SSH首次登陆提示),输入 yes 。然后按提示输入密码 hadoop,这样就登陆到本机了。

但这样登陆是需要每次输入密码的,我们需要配置成SSH无密码登陆比较方便。
7、首先退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
exit # 退出刚才的 ssh localhost
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权
提示:
在 Linux 系统中,~ 代表的是用户的主文件夹,即 “/home/用户名” 这个目录,如你的用户名为 hadoop,则 ~ 就代表 “/home/hadoop/”。 此外,命令中的 # 后面的文字是注释。
此时再用 ssh localhost 命令,无需输入密码就可以直接登陆了,如下图所示。

规范我们先在根目录下新建个文件夹pip 命令如下
cd /
mkdir pip
cd pip/
下载pip(可以使用wget 报错请使用curl -0)
wget https://pypi.python.org/packages/source/p/pip/pip-7.1.2.tar.gz
tar zxvf pip-7.1.2.tar.gz //解压安装包
cd pip-7.1.2 //移动到pip目录
python setup.py install //安装
ln -s /usr/local/python27/bin/pip2.7 /usr/bin/pip
//pip默认安装到了/usr/local/python27/bin下面
(此时如果已经安装pip,请将以前的pip更改名字,或者删除)
更改名字:mv /usr/bin/pip /usr/bin/pip_old
删除:rm -rf /usr/bin/pip
豆瓣电影提供最新的电影介绍及评论包括上映影片的影讯查询及购票服务。你可以记录想看、在看和看过的电影电视剧,顺便打分、写影评,极大地方便了人们的生活。
豆瓣电影是这样介绍自己的:“国内最权威电影评分和精彩影评,千万影迷的真实观影感受,为你的观影做决策。”而它也确实做到了这一点。
然而,前些日子,朋友圈又因一事沸腾了。《中国电影报》12月27日发布题为“豆瓣电影评分,面临信用危机”的文章,随后人民日报客户端转发了该文,并将标题改为“豆瓣、猫眼电影评分面临信用危机,恶评伤害电影产业”。
基于此,特地把以前抓取的豆瓣电影数据拿出来分析一下,重点比较中国电影与其他国家和地区的电影的差异,以为豆瓣评分正名。
这个数据只抓取到2016年上半年,总计 58127 部电影。包括id,电影名称,豆瓣评分,评分人数,上映时间,导演,主演,制片国家,影片简介等等信息。按照评分人数从高到低排序,数据库截图如下。
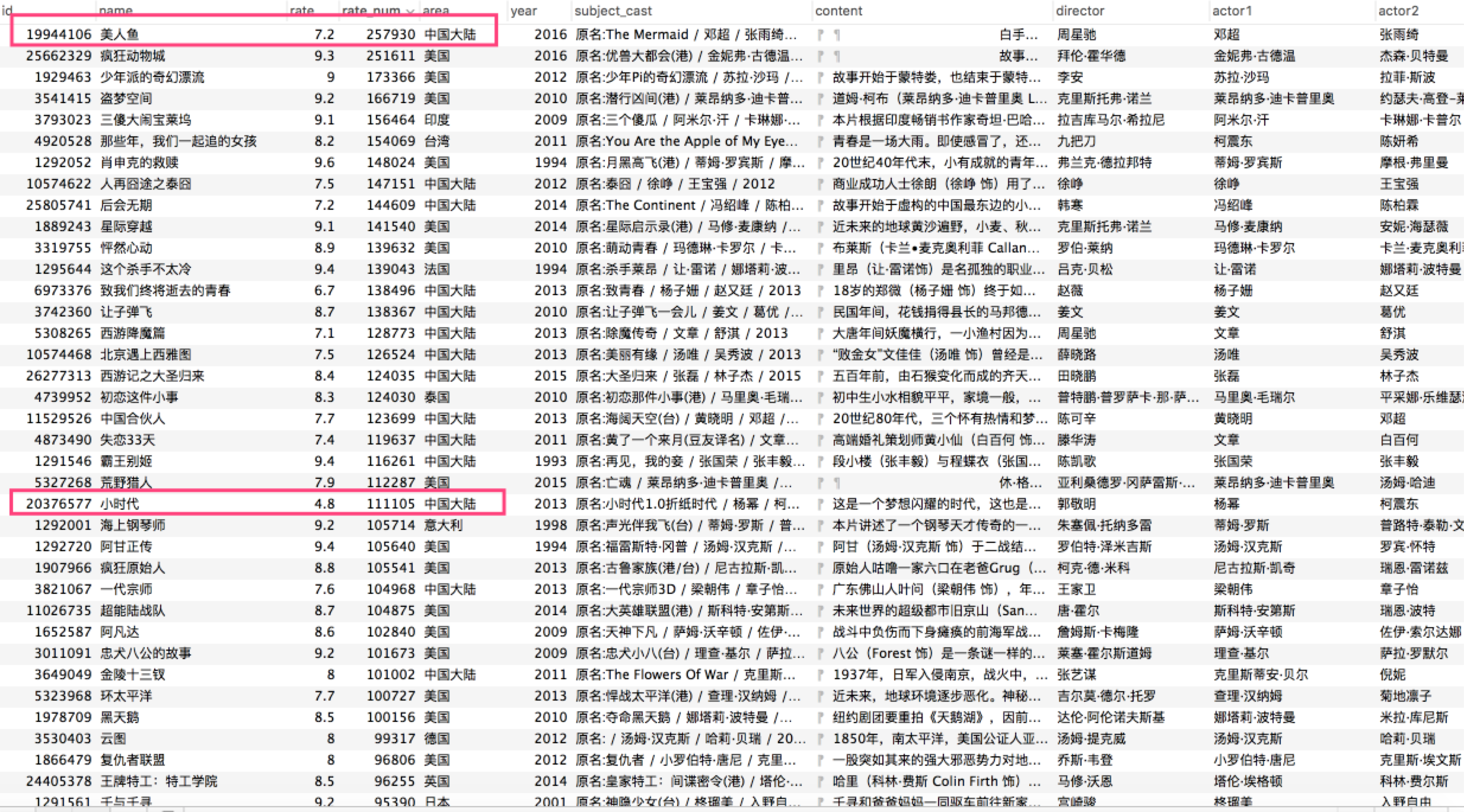
可以发现,评分人数最多的电影是周星驰的《美人鱼》,这是一部国产片,说明国人对国产电影还是非常关心的,并不像人民日报所抨击的那样——国人崇洋媚外,不关心国产电影。
另外,也可以发现,评分人数越多,电影得分基本在7.0以上,属于中等以上的好片。(《小时代》除外)




